#StopKillingGames initiative and explain why I believe it is fundamentally misguided. After carefully reviewing the arguments presented by proponents of this initiative, such as Ross Scott (aka Accursed Farms), and the counterarguments made by industry professionals like Thor (aka Pirate Software), I am convinced that this initiative fails to consider the realities of game development and could potentially harm both developers and players.
The Initiative's Unrealistic Expectations
One of the primary requirements of the #StopKillingGames initiative is that games must be left in a functional, playable state indefinitely, even after the developers decide to cease support[6]. While this may seem like a great goal, it is simply not feasible for many online-only live service games. Maintaining servers and infrastructure for games with dwindling player bases is economically unsustainable[1]. Forcing developers to release server binaries or carve off single-player experiences would not only be a massive undertaking but could also leave them vulnerable to abuse and unauthorized monetization of their intellectual property[1].
Furthermore, the initiative's FAQ fails to provide a realistic solution for large-scale MMORPGs[7]. Running these games requires significant resources and expertise that cannot be easily handed over to players when servers are shut down. The suggestion that developers should incorporate offline functionality or server hosting tools from the design phase onward[7] is an unreasonable burden that would stifle innovation and limit the types of games being created.
Misunderstanding the Economics of Game Development
The initiative fails to recognize the economic realities of game development, particularly for live service games such as MMOs and multiplayer online titles. These games require significant ongoing resources to maintain, and as player interest wanes, the cost of keeping them online often outweighs the benefits[1][9]. Mandating that developers maintain these games indefinitely could discourage the creation of new live service experiences, ultimately limiting player choice[1].
Moreover, the initiative's proponents seem to misunderstand the nature of microtransactions and in-game purchases. While these revenue streams are indeed crucial for live service games[9], they are not a guarantee of indefinite profitability. As player bases dwindle, so does the revenue generated from these sources, making it financially unfeasible to continue supporting the game[9].
Regardless of these points it fundamentally misses the point. That games are hard to make. That they are a risky undertaking to finance, build and sell. The end goal of the initiative in it's current state will make online first games even riskier limiting who will take that risk and ultimately what games will get made.
Vague Language and Lack of Focus
Another major issue with the initiative is its vague language and lack of focus on specific problematic business practices. Instead of targeting the entire gaming industry, efforts should be directed at instances where games are misleadingly marketed or where online-only requirements are unnecessarily imposed on single-player experiences[1]. By casting such a wide net, the initiative risks causing unintended consequences and harming developers who are acting in good faith[1].
The initiative's website[6] and FAQ[7] fail to provide clear guidelines on what constitutes a "playable state" or how developers should implement offline functionality. This ambiguity leaves room for misinterpretation and could lead to a situation where developers are forced to invest resources into features that do not align with their creative vision or the game's intended experience.
The Importance of Clear Communication
As developers, we have a responsibility to clearly communicate the nature of the games we create, especially when it comes to live service titles. Arguably, we play little to no role in the marketing and sale of the game, however we should be holding our counterparts in the Publishers accountable. Players should be explicitly informed that they are purchasing a license to access the game rather than buying the game outright[1]. This distinction is crucial, as it helps manage expectations and ensures that players understand the potential for games to be shut down or have their licenses revoked due to cheating or other violations of the terms of service[1].
While the initiative's proponents argue that the way games are sold and conveyed to players is problematic[5], the solution lies in promoting transparency and educating consumers rather than imposing blanket regulations on the industry. Publishers should be encouraged to clearly state the expected lifespan of their games and the conditions under which they may become unplayable, allowing players to make informed decisions about their purchases.
Preserving Gaming History Responsibly
While the initiative claims to be about game preservation, its proposed methods are flawed. Preserving online-only games in a state where they have few active players does not accurately capture the essence of what made these games special in the first place[1]. The social interactions and dynamic experiences that define these games cannot be replicated by simply making them playable offline or on private servers with a handful of players[1].
Moreover, the initiative's focus on preserving games in their original form fails to account for the evolving nature of the medium. Games are not static artifacts but living, breathing creations that change over time as developers release updates and patches[1]. By fixating on preserving games in their launch state, the initiative risks stifling the creativity and innovation that drive the industry forward.

This initiative is fundamentally not about preserving gaming history or anything so noble or academic; it is born from a temper tantrum and the twisting of French consumer law to serve the interests of a vocal minority at the expense of everyone else. The #StopKillingGames initiative claims to advocate for consumer protection and game preservation, but its underlying motivations appear to be rooted in dissatisfaction with the natural lifecycle of live service games and a desire to exert control over creative and business practices in the gaming industry.
Moreover, the use of consumer protection laws to achieve the goals of the #StopKillingGames initiative raises questions about the appropriateness of such legal actions and their potential unintended consequences. Consumer protection laws are designed to safeguard the rights of consumers, but their application in this context may be questionable and could potentially lead to negative outcomes for the industry and consumers alike.
Instead of forcing developers to maintain games indefinitely, we should focus on supporting efforts to document and archive the history of these titles in a way that respects the creators' intellectual property rights and the realities of the industry[1]. Initiatives like the Video Game History Foundation[4] and the Internet Archive[4] are already doing valuable work in this area, and their efforts should be supported and expanded.
The Dangerous Implications of Forced Server Binary Releases
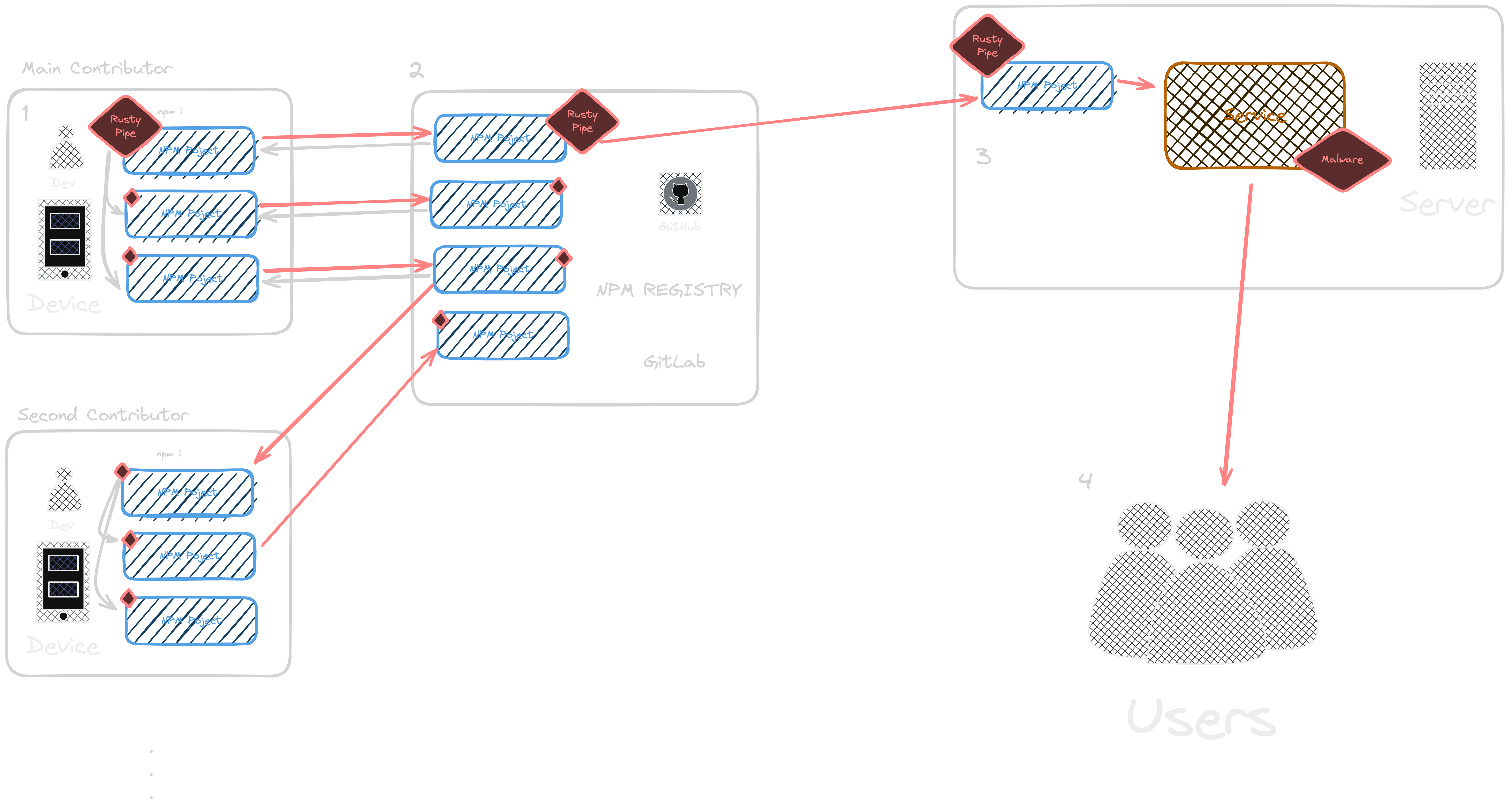
One of the most alarming points raised by myself and others is the potential for abuse that the #StopKillingGames initiative could enable. Under the proposed requirements, developers would be legally compelled to release server binaries or keep games in a functional, playable state indefinitely. This opens the door for bad actors to deliberately target and attack game studios, with the goal of forcing them to release their intellectual property. Thor had great examples like TF2. See below.
Condsider this scenario:
A malicious individual or group decides to target a specific game studio. They begin by bombarding the studio's live service game with bots, exploits, and attacks on the game's community. They flood forums and social media with negativity, driving away legitimate players and making it increasingly costly for the studio to maintain the game. As the player base dwindles and the studio's resources are drained, they may be forced to shut down the game.
Under the #StopKillingGames initiative, the studio would then be legally required to release the game's server binaries. The attackers, having successfully driven the studio to this point, can now take those binaries and create their own private server, monetizing the studio's work for their own gain. This is not a hypothetical situation; as Thor points out, we've seen similar tactics used in the past, such as the bot attacks on Team Fortress 2.
This legislation would essentially make it legal for bad actors to deliberately destroy a company and take their work. It's a dangerous precedent that could have a chilling effect on the entire gaming industry. Studios would be hesitant to create live service games, knowing that they could be targeted and forced to give up their intellectual property. This would limit innovation and creativity, ultimately harming both developers and players.
It's crucial that any initiative or legislation aimed at protecting consumers takes into account the potential for abuse. The #StopKillingGames initiative, as it is currently written, fails to do so. By compelling developers to release server binaries, it creates a system that can be exploited by those with malicious intent. This is not a solution to the problem of games being shut down; it's a recipe for disaster that could have far-reaching consequences for the industry as a whole.
The Dangers of Misrepresenting the Initiative
Finally, I find the tactics used by some proponents of the initiative, such as Ross Scott, to be disingenuous and potentially harmful. Suggesting that politicians will blindly support the initiative because they don't care about the gaming industry and that it's an easy win for them[2] is not only inaccurate but also sets a dangerous precedent. The gaming industry is a significant contributor to the global economy[8], and politicians are unlikely to make decisions that could harm its growth and innovation without careful consideration.
Furthermore, the comparison to loot box laws[7] is misleading, as those regulations targeted a specific predatory practice rather than imposing broad requirements on game development and preservation. If we are to advocate for change, we must do so in a way that is honest, well-informed, and respectful of all stakeholders involved.
Wrapping Up
At the end of the day, while I appreciate the sentiment behind the #StopKillingGames initiative, I cannot support it in its current form. The initiative's unrealistic expectations, misunderstanding of game development economics, vague language, and misguided preservation methods make it a flawed approach to addressing the issues it aims to tackle.
As a developer who is passionate about creating meaningful experiences, I believe that our focus should be on promoting clear communication, encouraging responsible preservation efforts, and targeting specific problematic practices rather than broadly condemning the entire industry. By working together and engaging in honest, nuanced discussions, we can find solutions that protect both players and developers while fostering a vibrant and innovative gaming landscape for years to come.
Citations:
[1] https://www.reddit.com/r/pcgaming/comments/1elgpii/stop_killing_games_an_opposite_opinion_from/
[2] https://www.stopkillinggames.com
[3] https://www.reddit.com/r/ffxiv/comments/1ejqjxm/the_european_initiative_stop_killing_games_is_up/
[4] https://news.ycombinator.com/item?id=41159063
[6] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files
[7] https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files
]]>